

The Cloud AI Trap
The big names — OpenAI, Anthropic, Google — have made AI accessible and powerful.
But they come with strings attached:
- Data leaves your environment — Even with secure enterprise contracts, prompts and responses travel over the public internet to a provider’s data centre.
- Costs grow unpredictably — Token pricing looks cheap on paper, but scales fast. A few busy users can rack up hundreds or thousands a month without warning.
- Model churn — Providers can swap or tweak model versions overnight, changing output quality without notice.
- Compliance delays — If you work in regulated sectors, every new cloud integration means risk assessments, legal reviews, and potential deployment delays.
For many businesses, these issues create a Catch-22:
AI could help them move faster, but they’re stuck waiting for the green light — or they just absorb the risk and hope for the best.
The In-House Alternative
Running your own AI models inside a Dockerized sandbox changes the equation.
- Full control — The models, logs, and vector stores live in your own environment (on-prem or private cloud VM).
- Predictable costs — You buy or rent hardware with a fixed monthly cost. No surprise bills for token usage.
- Version stability — You pin the model version you want. No silent changes by a vendor.
- Faster experimentation — Spin up a testbed in hours without a months-long compliance review.
With tools like Ollama, you can pull and run top-tier open-weight models (Meta Llama 3, Qwen 2.5, Mistral, etc.) locally — all orchestrated in a clean, disposable Docker Compose stack.
How It Works
At its simplest, the setup looks like this:
- Dockerized Ollama hosts the AI model.
- FastAPI gateway in front of Ollama applies guardrails, logging, and authentication.
- Vector database (Postgres + pgvector) enables retrieval-augmented generation (RAG) from your own content.
- Object storage (MinIO or Azure Blob) keeps artifacts and datasets.
- Reverse proxy (Traefik) secures connections and manages routes.
Everything lives on a private network you control. No prompt or response leaves your infrastructure unless you choose to send it.
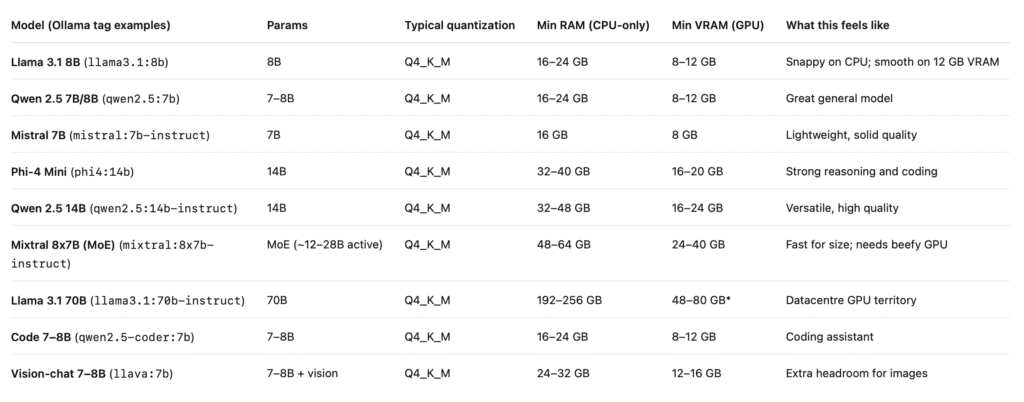
Hardware Requirements for Top Ollama Models
Why This Matters
Cloud AI is powerful, but if you care about cost control, data governance, and stability, moving part or all of your AI workloads in-house is a strategic win.
A Dockerized Ollama sandbox gives you predictable monthly spend, full control over models and data, fast experimentation, and the freedom to evolve on your terms.
StayFrosty!
~ James
Q&A Summary:
Q: What are some disadvantages of using big name Cloud AI providers?
A: Disadvantages include data leaving your environment, unpredictable costs, providers changing model versions without notice, and compliance delays.
Q: What are the benefits of running your own AI models in a Dockerized sandbox?
A: Benefits include full control, predictable costs, version stability, and faster experimentation.
Q: What is the role of Dockerized Ollama in running your own AI models?
A: Dockerized Ollama hosts the AI model.
Q: What are the components of the setup for running your own AI models with Ollama?
A: The setup includes Dockerized Ollama, a FastAPI gateway, a vector database, object storage, and a reverse proxy.
Q: What are the benefits of running AI models with tools like Ollama?
A: Benefits include the ability to pull and run top-tier open-weight models locally, all orchestrated in a clean, disposable Docker Compose stack.